计算机网络-网络层
网络层
分类编址的IPv4地址
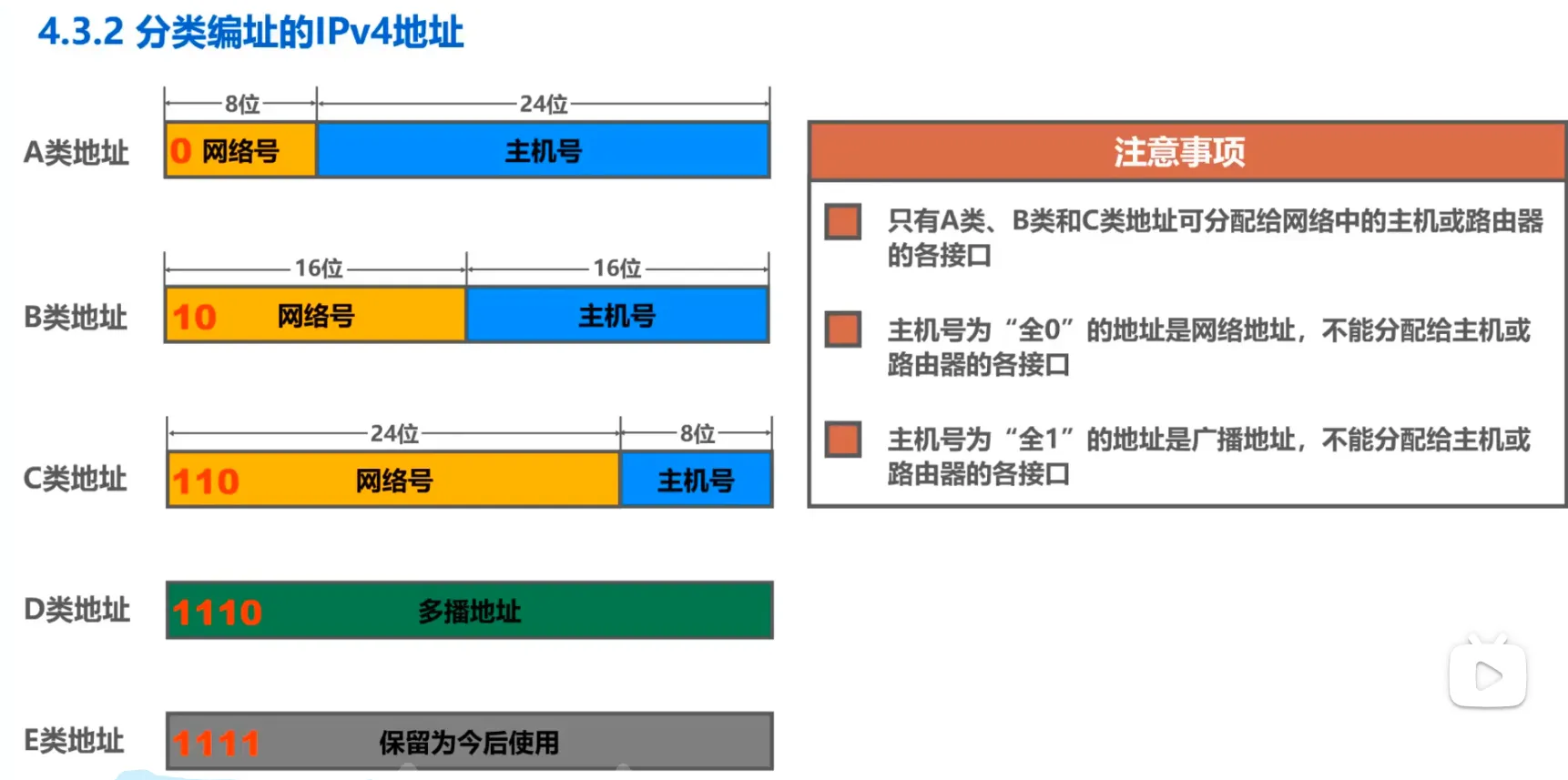
A类地址
最小网络号为0, 保留不指派
第一个可指派的网络号为1, 网络地址为1.0.0.0
最大网络号为127, 作为本地环回测试地址,不指派
- 最小的本地环回测试地址为127.0.0.1
- 最大的本地环回测试地址为127.255.255.254
最后一个可指派的网络号为126
可指派的网络的数量为126, 每个网络中可以分配的IP地址数量为2^24 - 2 = 16777214 (减2是取出全0的网络地址和全1的广播地址)
B类
最小网络号128, 最大网络号191.255
可指派网络数为2 ^ (16 - 2) = 16384, 每个网络中可分配的IP地址数量为2 ^ 16 - 2 = 65534
C类
最小网络号192, 最大网络号223.255.255
可指派的C类网络数量2 ^(24 - 3), 每个网络中可分配的IP地址数量为2 ^ 8 - 2
划分子网的IPv4地址
为了减少IP的浪费,把一个大的IP地址切分为多个小的子网
结构变为<网络号><子网号><主机号>

无分类编址的IPv4地址
即使有了划分子网,但是还不够彻底,仍然有巨大的浪费
Classless Inter-Domain Routing (无分类域间路由)CIDR 使用斜线记法,可以在 IP 后面直接写 /n,表示前 n 位是网络前缀
路由聚合(构造超网)
将多个较小的子网和1并成一个较大的网络
网络前缀越长,路由越具体,如果路由器查表转发分组的时候发现有多条路由可以选择,则选择网络前缀最长的那个,这样的路由更具体
IPv4地址的应用规划
采用 VLSM (可变长子网掩码),根据实际的主机数量,按需分配
IP数据报的发送和转发过程
主机A给B发送数据,先将自己的IP地址与子网掩码进行与运算,得出自己的网络号。然后将目标IP地址与子网掩码与运算,得到目标地址的网络号,如果相同,说明在同一个子网内,主机A直接发送给B。如果不同,说明不在同一个子网内,主机A将数据发送给默认网关(通常是路由器),路由器拿着目的IP地址与自己路由表里的条目逐条匹配,如果找到,就将数据发送
匹配算法
-
用路由表中每一行的掩码与目标 IP (D) 做 AND 运算。
-
如果结果等于该行的目的网络地址,则匹配成功。
-
如果有多行匹配成功,选择掩码最长(最精确)的那一行。
-
如果没有一行匹配,丢弃数据报,向源主机报错(ICMP 目的不可达)
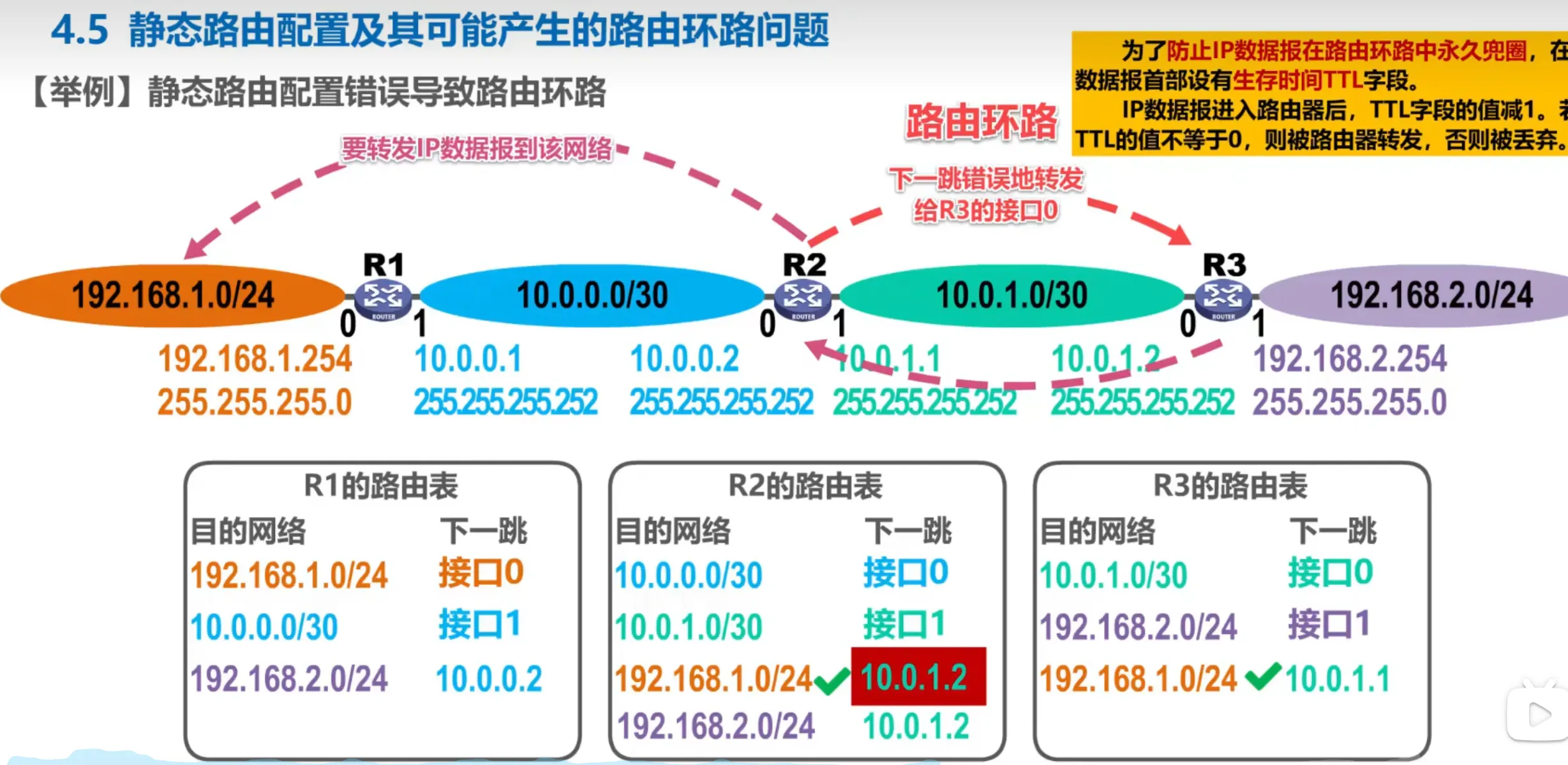
静态路由配置及其可能产生的路由环路问题
- 互指的错误
- 路由汇总 + 错误聚合
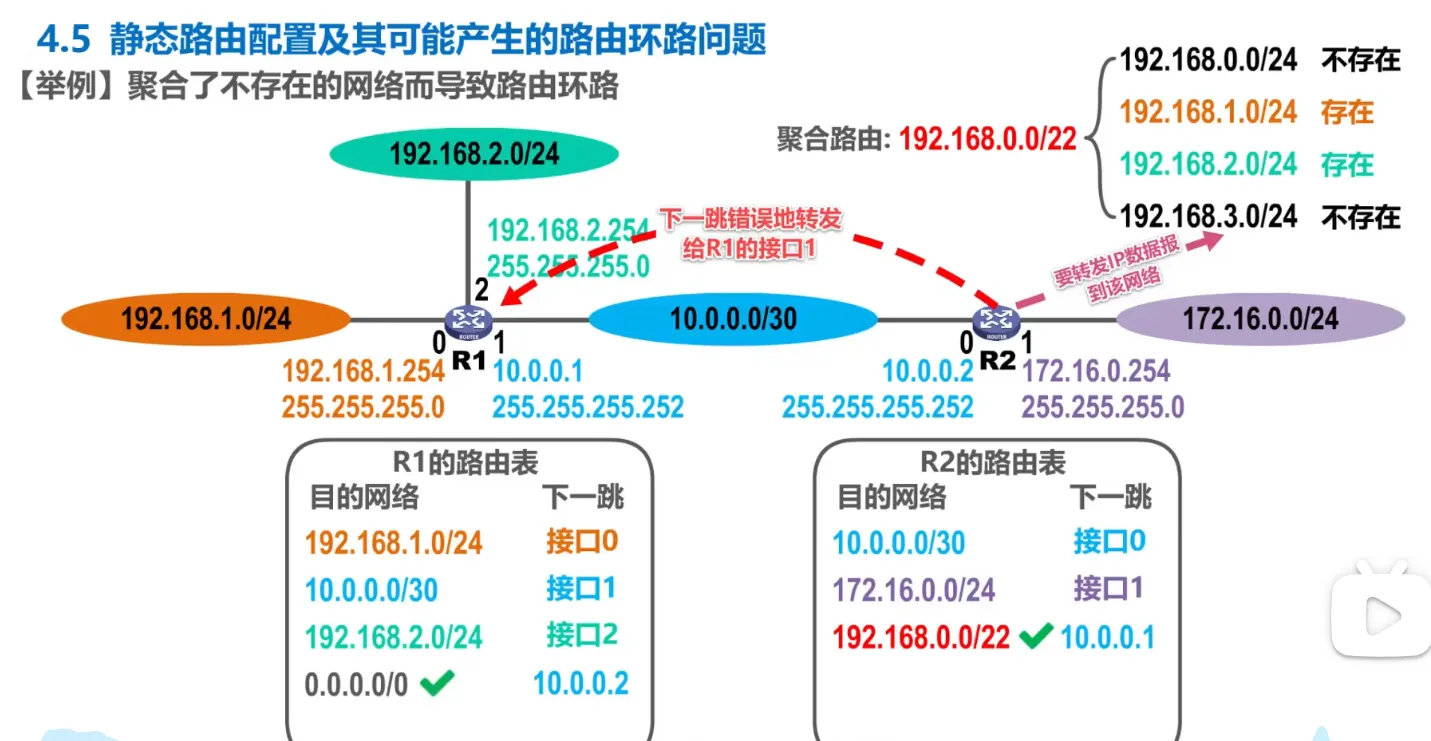
针对情况2,使用黑洞路由解决。
如果路由器查表的时候有多条能够匹配,使用最精确的那一条
-
正常流量 (如 192.168.1.1):
-
路由器上有具体的明细路由(比如是通过动态路由学到的,或者是直连的)。
-
明细路由
/24比 Null0 的汇总路由/16更长。 -
结果: 正常转发,不会被丢弃。
-
-
异常流量 (如 192.168.3.1):
-
路由器上没有
.3.0的明细路由。 -
此时,它匹配到了我们刚写的
192.168.0.0/16 -> Null0。 -
虽然可能还有默认路由指向外网,但
/16比/0(默认路由) 长。 -
结果: 路由器直接把包扔进垃圾桶 (Null0)。环路被切断了!
-
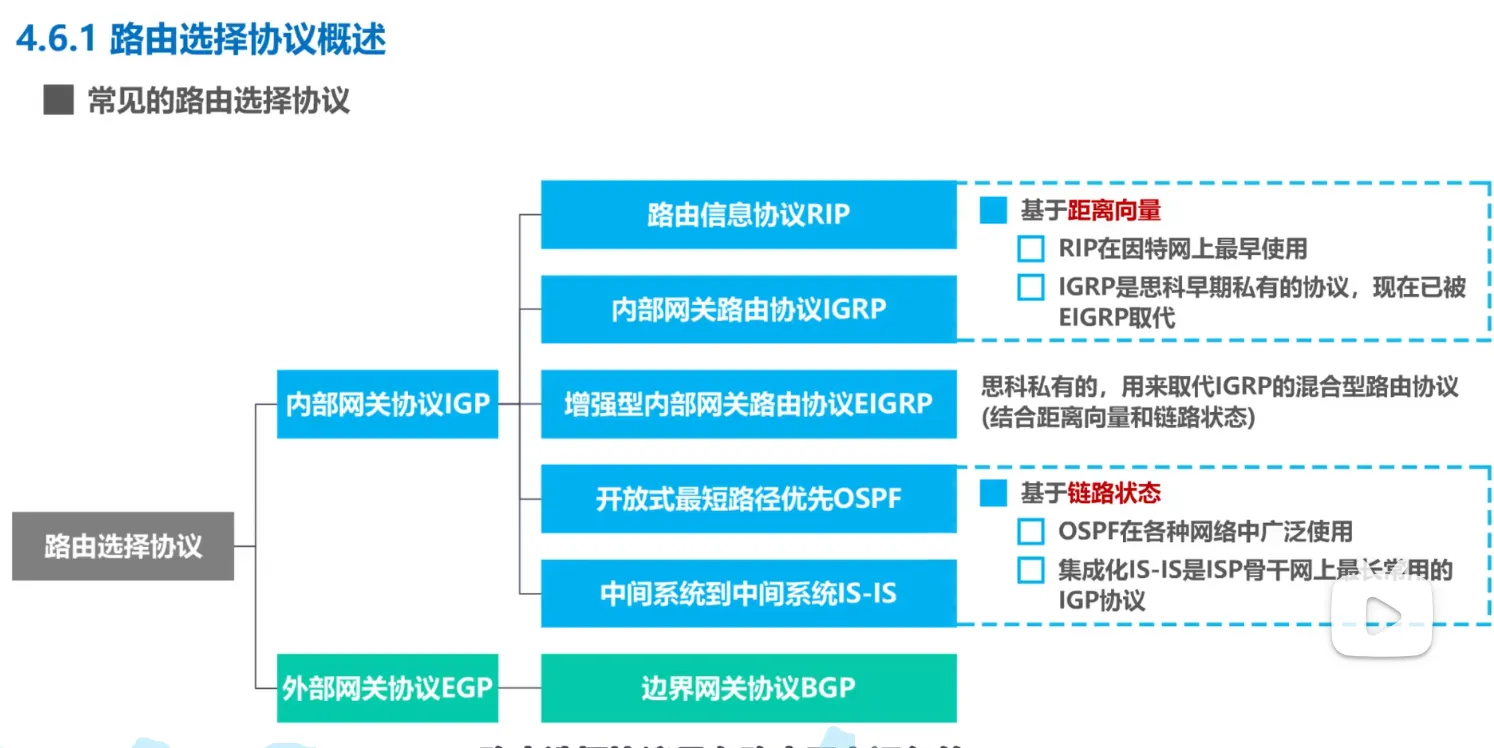
路由选择协议

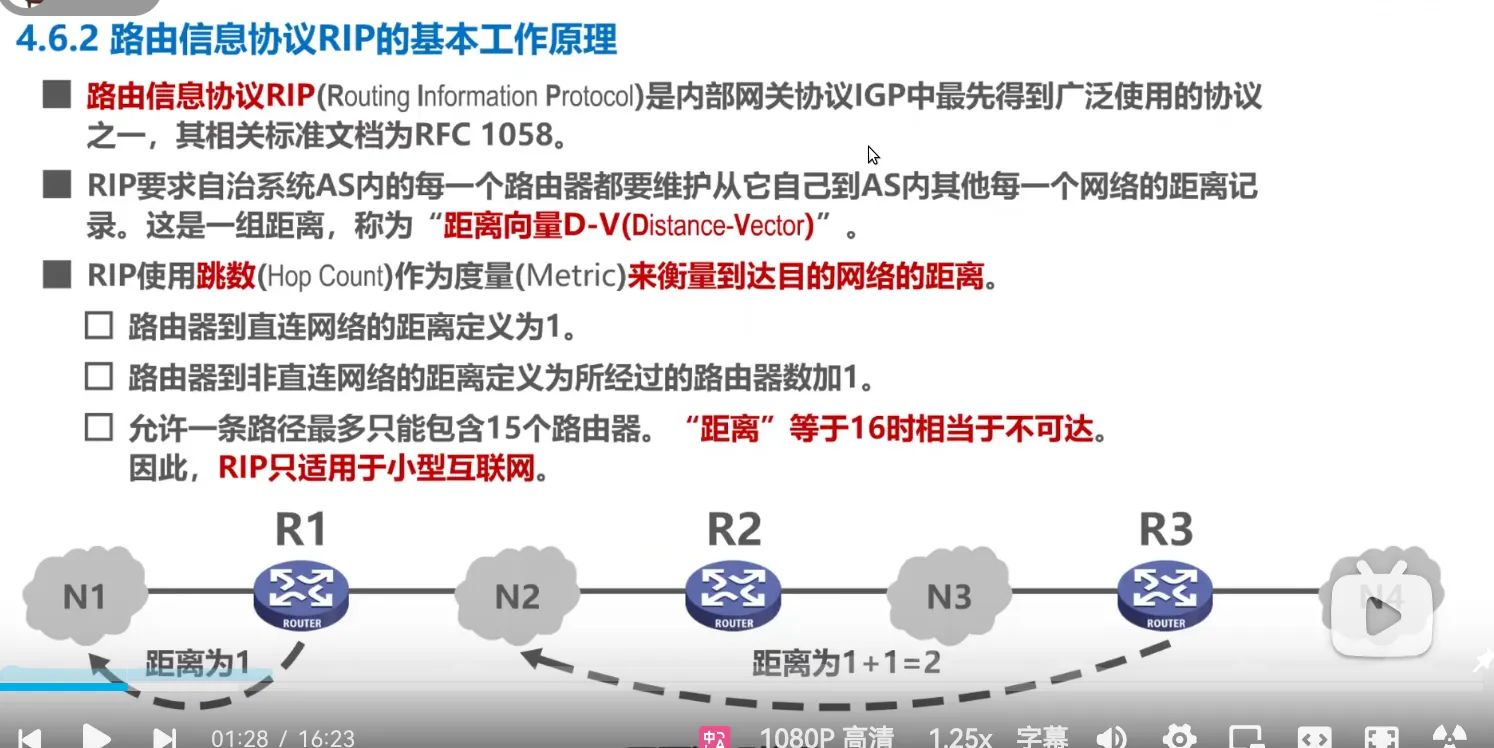
RIP的基本工作原理
更新过程
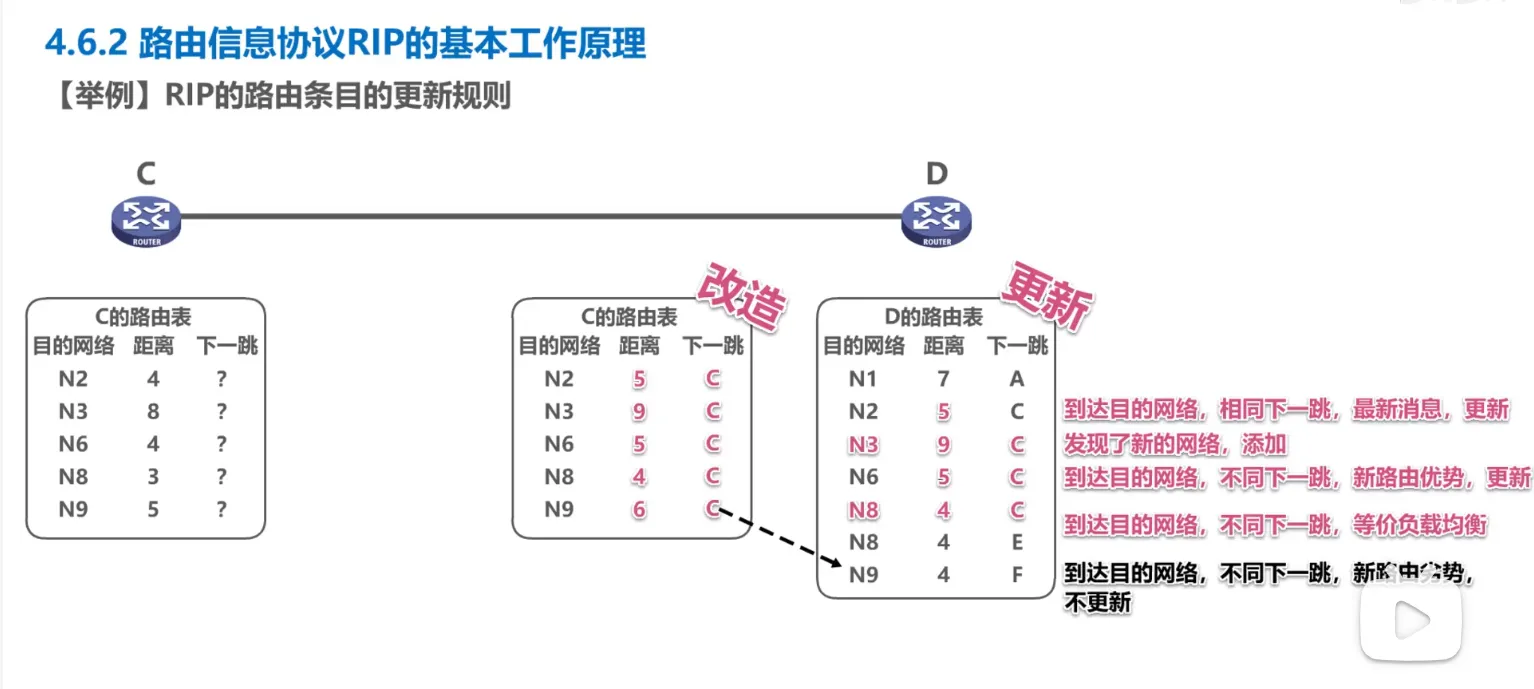
- 路由器B收到了路由器A的路由表
- 改造信息: B收到了A的路由表后, 把所有的举例都加1, 下一跳都改为A(B是A的相邻表,距离加1跳)
更新原则:- 新路线: A知道网络X怎么去,距离是x, B不知道, 直接添加
- 更短路线: A到网络Y要2跳,B到Y原本走C要5跳,更新,以后到Y走A
- 同源更新: A到网络Z需要10, B原本就是走A到Z的只需要3跳, 更新
- 更差的路线: 不管
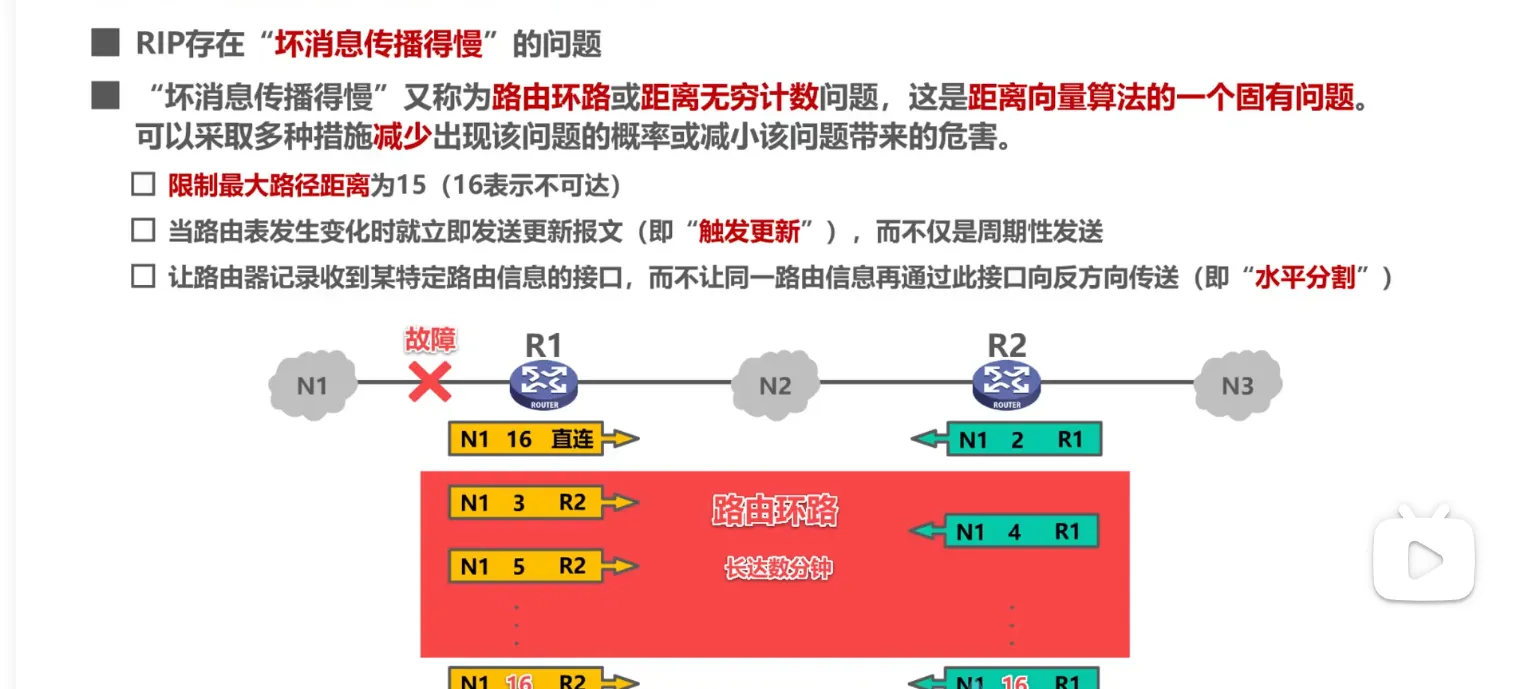
RIP的缺点:坏消息传的慢(慢收敛)
-
路由器 A 连着网络 N,A 告诉 B:“去 N 只要 1 跳”。
-
B 告诉 C:“去 N 只要 2 跳”。
-
突然,A 和 N 断了。A 将去 N 的距离改为 16(不可达)。
-
但在 A 的更新包发给 B 之前,B 抢先给了 A 一个更新:“嘿,去 N 走我这里只要 2 跳哦!”(这是 B 之前从 A 那里听来的旧闻)。
-
A 傻了:“哦?你能去 N?那我把数据给你,距离变成 3。”
-
A 和 B 开始互相欺骗,距离从 3 涨到 4,4 涨到 5… 直到涨到 16。
-
这就是 “计数到无穷” (Count-to-Infinity) 问题,形成了路由环路。
OSPF的基本工作原理
- OSPF是基于链路状态的,而不是像RIP一样基于距离向量
- 采用Dijkstra提出的最短路径算法SPF计算路由, 从算法上保证了不会产生路由环路
- 不限制网络规模, 更新效率高,收敛速度块
- 链路状态是指本路由器和哪些路由器相邻以及相映链路的“代价“
工作流程
- 建立邻居关系
相邻路由器通过交互问候(hello)分组, 建立和维护邻居关系-
动作: 只要两个路由器互相收到了对方的 Hello 包,它们就建立了邻居关系 (Neighbor Relationship)。
-
目的: 确认链路是通的,并确立“我们俩要开始交换信息了”。
-
维持: 之后也会周期性发送 Hello 包(通常 10秒一次)作为“心跳”,如果 40秒(Dead Time)没收到邻居的 Hello,就认为邻居挂了。
-
- 链路状态洪泛
使用OSPF的路由器会产生链路状态通告(LSA), LSA中包含直连网络的状态信息, 相邻路由器的链路状态信息,与相邻路由器间的”代价“-
泛洪 (Flooding): 每个路由器都会把自己的 LSA 发给邻居,邻居收到后,原封不动地拷贝一份发给它的邻居。
-
结果: 就像连锁反应一样,最终全网所有的路由器都收到了每一台路由器的 LSA。
-
- 构建链路状态数据库(LSDB)
将收集到的LSA存到数据库中 - 计算最短路径
有了LSDB,路由器开始运行 Dijkstra 算法,构建出到达其他各路由的最短路径, 即构建路由表
区域
如果网络特别大, LSDB会变得巨大, 为了使SPF可以用于大规模的网络,OSPF把一个自治系统划分为若干小范围的系统,叫做区域

边界网关协议BGP

BGP 是目前互联网上唯一使用的 EGP (外部网关协议)。它的核心任务不是“找最快的路”,而是**“找一条能走、且符合策略(Policy)的路”**

IPv4数据报的首部格式
网际控制报文协议ICMP
- 终点不可达
- 源点抑制
路由器或主机由于拥塞而丢弃数据时,向源点发送源点抑制报文,使源点知道应当把数据报的发送速率减缓 - 时间超过
- 参数问题
- 改变路由(重定向)
以下情况不发送ICMP
- 对ICMP差错报告报文不发送ICMP差错报告报文
- 对第一个分片的数据报片的所有后续数据报片不发送ICMP差错报告报文
- 对具有多播地址的数据报都不发送ICMP差错报告报文
- 对具有特殊地址(如127.0.0.1或0.0.0.0)的数据报不发送
常见的ICMP询问报文
- 回送请求和回答
由主机或路由器向一个特定的目的主机发出的询问,收到此报文的主机必须给源主机或路由器发送ICMP回送回答报文。
这种报文用于测试目的站是否可达 - 时间戳请求和回答
请某个主机或路由器回答当前的日期和时间
进行时间同步和测量时间
ICMP应用
- ping
- traceroute
虚拟专用网VPN与网络地址转换NAT

运输层
UDP与TCP对比
UDP(user datagram protocal) tcp(transmission control protocal)
UDP
- 无连接
- 支持一对一, 一对多,多对多,多对一交互通信
- 对应用层交付的报文直接打包
- 尽最大努力交付,不可靠,不使用流量控制和拥塞控制
- 首部开销小,只有8个字节
TCP - 面向连接
- 只能一对一传输
- 面向字节流
- 可靠传输,使用流量控制拥塞控制
- 首部最小20字节,最大60字节
TCP的流量控制
如果发送方发送数据过快,接收方可能来不及接受,这回导致数据的丢失。
流量控制就是让发送方的速率不要太快,让接收方来的及接收
利用滑动窗口机制可以在TCP上实现对发送方的流量控制
滑动窗口
- 接收方每次发送确认报文的时候,都会在窗口字段填入当前自己的缓冲区还有多少空间
- 发送方收到ACK后,更新自己的发送窗口,保证已经发送但未收到确认的数据量<=接收方的通知窗口大小
- 接收方读取了缓冲区的数据,有更多的空间,会发送一个新的ACK告诉发送方,发送方的窗口向右滑动,继续发送
窗口关闭
如果接收方缓冲区已经满了,会发送一个窗口为0的报文,此时发送方停止发送
但是这又有一个新的问题,如果接收方处理了数据,有空余的空间,发送一个窗口增加的报文,但是这个报文在网络中丢失了,怎么办? 这会导致死锁
解决方案:窗口关闭时,发送方启动一个定时器,周期性的向接收方发送一个字节数的探测报文,接收方收到后必须回复当前窗口的大小,这样就不会死锁
TCP的拥塞控制
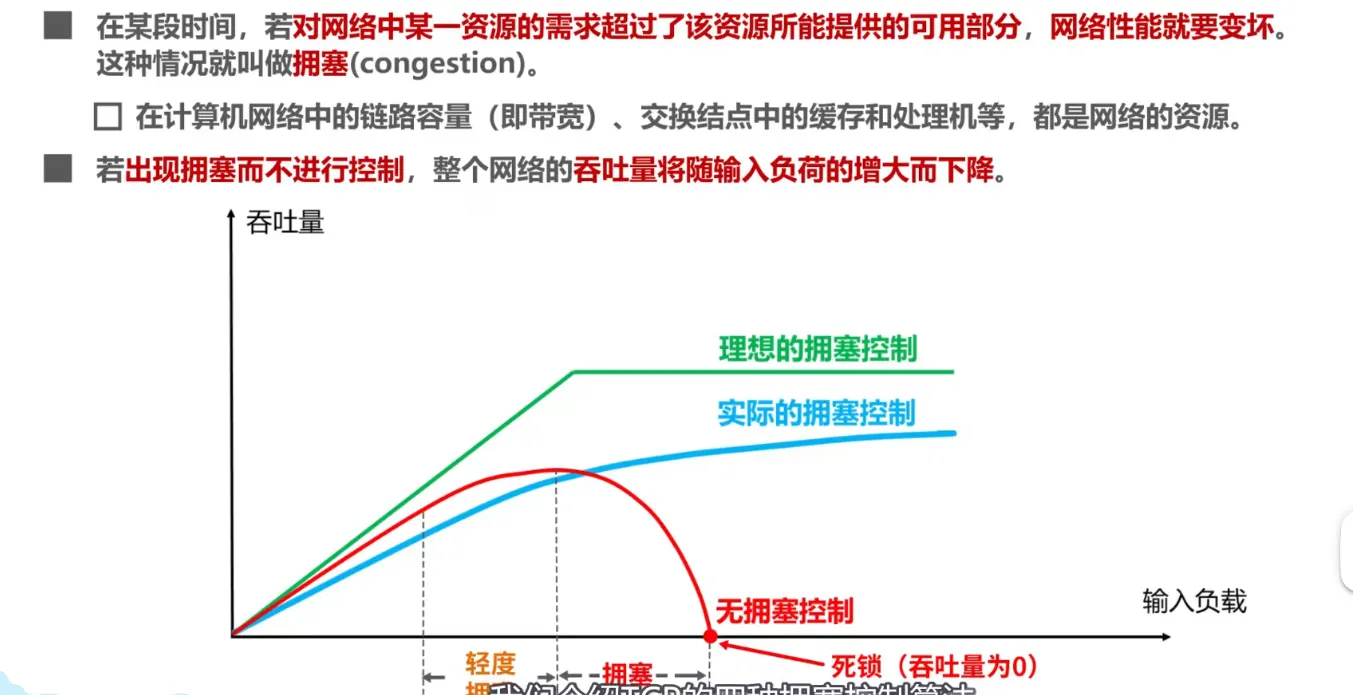
拥塞控制是一个不断试探网络的过程,一旦发现丢包,就立即减少发送量,然后再慢慢增加
关键变量:cwnd (拥塞窗口) 和 ssthresh (慢启动阈值)
cwnd: 发送方可以发送的数据量,不考虑接受方能不能接受
ssthresh:是慢启动与拥塞避免阶段的分界
-
慢启动
刚开始建立连接时,不知道网络状况什么样,从极小的大小开始试探
初始cwnd=1,发送数据,每收到一个ACK就+1
每次窗口都翻倍增长
当cwnd增长到>=ssthresh时,慢启动结束,进入拥塞避免阶段 -
拥塞避免
不再翻倍增长,而是每经过一个发送确认周期,cwnd大小只增加1
直到网络出现丢包结束 -
拥塞发生
- 严重拥塞
发送方迟迟收不到 ACK,直到定时器(RTO)超时。TCP 认为网络可能瘫痪了,反应非常剧烈。
ssthresh设置为当前cwnd的一半,然后将cwnd大小重置为1,重新进入慢启动阶段 - 轻微拥塞
发送方收到了连续3个重复的ACK(这说明中间有包丢失了,但是后面的都收到了),TCP认为网络还行,不需要重置为1,进行快重传,快恢复- ssthresh设置为cwnd的一半
- 将cwnd设置为ssthresh + 3(3是那三个重复的ACK)
- 进入快恢复
- 严重拥塞
-
快恢复
-
如果继续收到重复的 ACK,说明还有后续数据包到达了(都在网络里),
cwnd继续 +1。 -
直到收到新的 ACK(确认了重传的数据包),说明丢包已经补上了。
-
退出快恢复:将
cwnd设置为ssthresh(即刚才减半后的值),然后进入拥塞避免阶段(线性增长)。
-

TCP超时重传
TCP 超时重传时间 (RTO, Retransmission TimeOut)
RTT:数据包从发送到收到ACK的往返时间
如果RTO设置的时间太短,没有丢包也会认为丢包,产生不必要的重传,如果设置的时间太长,真发生丢包的时候,重传太慢,效率也很低
TCP采用动态算法计算RTO,让RTO的时间略大与RTT


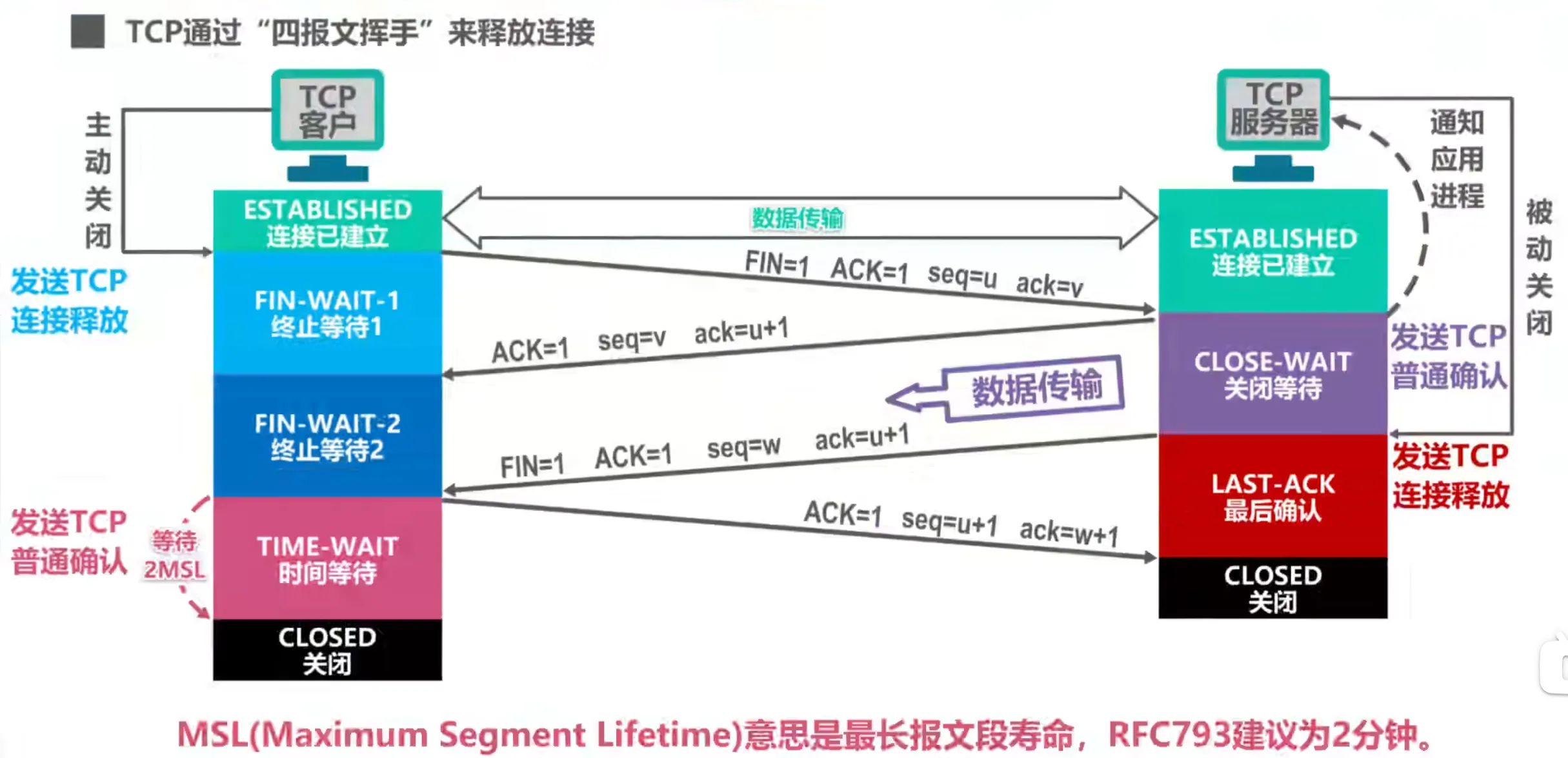
TCP的连接建立
三次握手
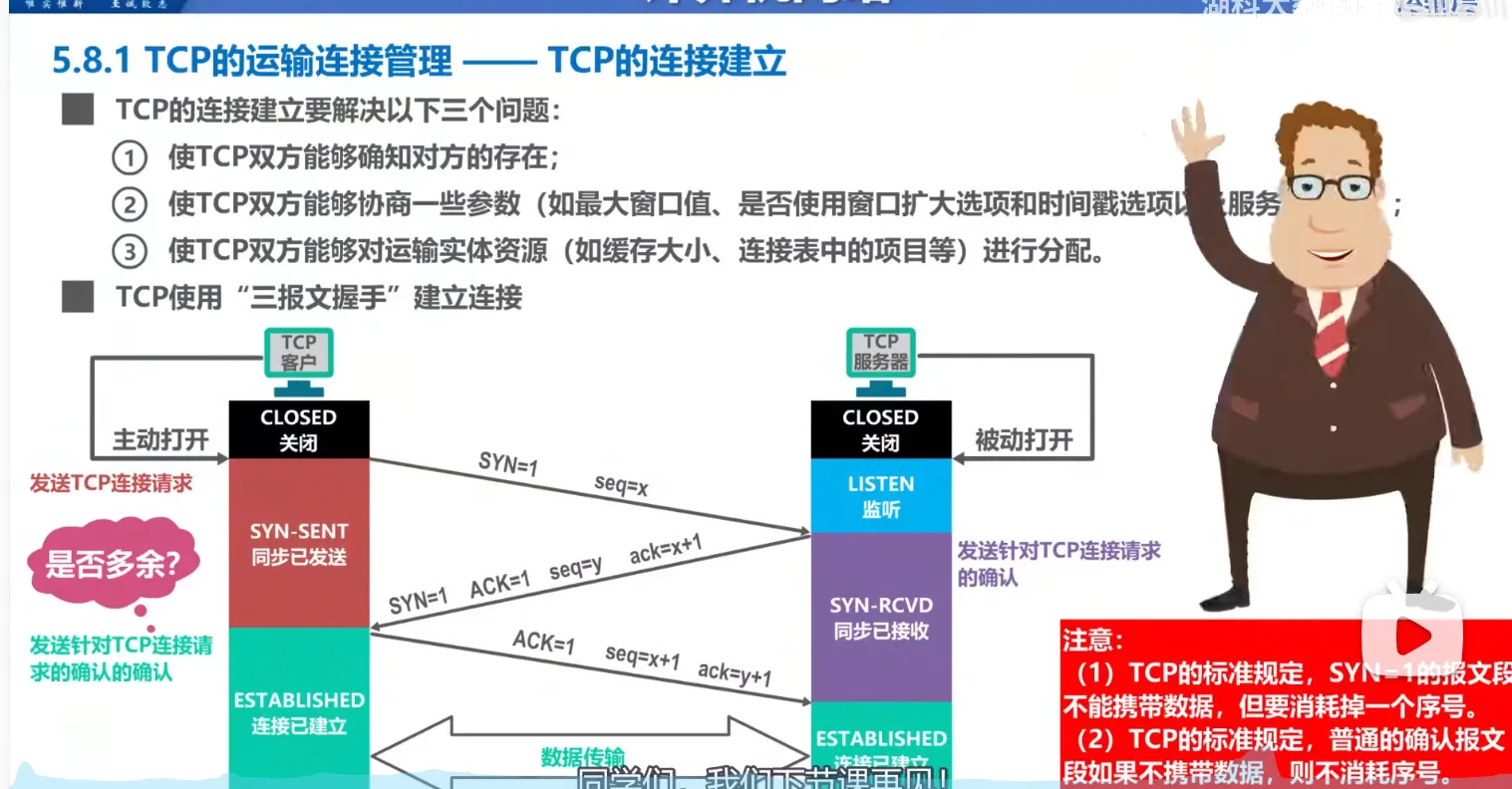
- 最初都处于close状态
- TCP服务器进程首先创建传输控制快,然后等待TCP客户端的连接请求,进入监听状态,
- 客户端随机生成一个初始序列号 。发送报文。报文内容:
SYN=1,seq=x - 服务器收到请求,同意建立连接。它需要确认客户端的 ,同时自己也生成一个初始序列号 。报文内容:
SYN=1,ACK=1,seq=y,ack=x+1。 - 客户端收到服务器的同意。需要对服务器的 进行确认。报文内容:
ACK=1,seq=x+1,ack=y+1- 客户端发送后,进入
ESTABLISHED(已建立连接) 状态。 - 服务器收到后,也进入
ESTABLISHED状态
为什么必须是“三次”,两次行不行?
防止“已失效的连接请求”突然到达
- 客户端发送后,进入
-
客户端发了第一个请求(A),但在网络里滞留了
-
客户端看 A 没回复,以为丢了,又发了一个请求(B)。
-
B 顺利完成了连接、传输、断开。
-
过了一会儿,滞留的 A 终于到了服务器。
-
如果是两次握手: 服务器收到 A,以为客户端又要建新连接,立刻回复“好的”,连接就建立了。服务器开始傻等客户端发数据,浪费资源。
-
如果是三次握手: 服务器收到 A,回复“好的”(第二次握手)。客户端收到后,发现:“咦?我没想建连接啊,这是旧消息。”于是客户端拒绝发送第三次确认。服务器收不到确认,就知道连接建立失败,释放资源。
第三次握手是可以携带数据的,前两次握手是不可以携带数据的
TCP连接关闭